最近流行ってる人工知能(AI, Artificial Intelligence)のお仕事

全てが同じ?
だと思ったら問題あります。
まずAIを語る前にデータ分析のお話から始めましょう。
データを分析するとき必要な分野は大きく3つに分けられます。
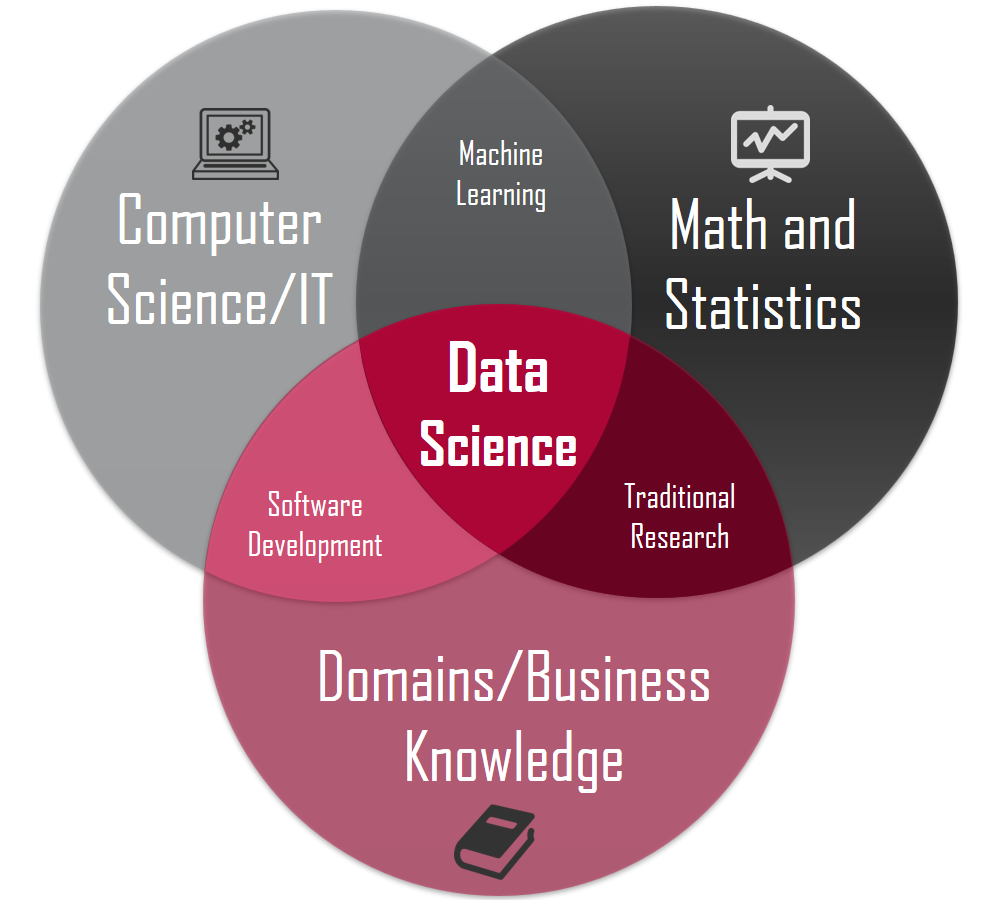
Data Analyst:数学と科学専門のデータだけ分析できる人
Domain Specialist : 該当分野のビズネスをはっきり分かってデータが意味するのを分かっている業界専門家
Hacker : コンピュータ専門のサーバーとデータストレージを自由にコントロールできる人。
この中でDomain Specialistは元々その業界にいるのであまり気にしてません。
今一番Data Scientistとして知られているのがData Analystです。
この人はMLライブラリを利用してデータを回すだけ。もちろん経験によって分析の品質と分析の方法、手順が変わって全然違う結果になってしまいますが、これはある程度決まってました。
実は、これだけでありません!
実は、これだけでありません!
データ収集専門家:
必要なデータの大半はインターネット上にあるのであれを大量に持ってくる技術をCrawlまたはScrapingと言います。今までは検索エンジンなどでしかあまり使ってないですが、現在はMLでは必ず必要な部門になりました。
インターネットからHTMLデータを抽出してURLをParsingしたらイメージ、リンクなどを分けてまたCrawlを続け必要な本文だけ持ってくるのにかなりの経験が必要です。
これが前処理の最初に必要な技術でこれだけの専門家がいます。
一つの検索エンジンからたくさんのリクエストをしたりするとブロックされるのでProxyを自由に利用するとかの細かい経験が必要な分野です。技術力より経験が必要な部分ですね。
自然語処理専門家(言語処理専門家):
次は拾ったデータと元々あったデータの中で言語から必要な単語抽出及び基本形を単語とか名詞だけ抽出するのがNLP(Natural Language Processing、自然語処理)で前処理専門家の技術の一つです。この人がLDA(https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation、潜在的統計トピックモデル抽出手法)などもやって本文の内容から言いたいトピックなども抽出したりして文章のカテゴライズを最初に行ったりもします。ML専門家(データ分析専門家):
その次が実際データを利用してMLモジュールを流すML専門家。
MLモジュールがやってるから実際やることないじゃない?と思ってる方もいらっしゃると思いますが、かなり多いMLモジュールの中でどのような方法でどの順番でやった方がいいか、Supervisedが必要な時どこでMLにTagを教えないといけないか、人の手間がかからないTagging手段はあるのかを考えないと行けません。
単純に銀行から貸出できる人を選ぶにLogistic RegressionだけしていいのにWord2Vecを使ってたりする無駄を省くのもここでやるべきの仕事です。
業界スペシャリストと共同にデータを見ながらやらないと時間がかなりかかります。
この経験が足りなくて1次データの検証だけで3ヶ月掛かったことも実際ありました。
Front開発者:
そのあとデータの視覚化などはWeb関連になるのでData Scientistには含まれてないですが、Data Scientist関連企業では必須です。
Bootstrapなどを利用しえいかにVisualizationがしやすくなるのかによっていいデータでも売れなくなったとか、よくないデータでも売れてるとかします。
この分野の人は「Web Front開発者」と言います。
この分野の人は「Web Front開発者」と言います。
これで終わりと思ってる方が多いと思いますが、Hackerという分野が残ってます!
Hackerというところは未だにも分かってないところが多いでしょう。
Hacker(システム専門家・アーキテクト):
Cloudになってきて自由に拡張できるストレージとコンピュティングパワーということはもっと管理が難しい状況になって必要な時数PB(Peta Byte、1PB ≒ 1,000,000GB)のデータストレージが生成できて必要なくなったらすぐなくせる、そしてデータの整合性を維持する、並列コンピュティングプロセスを管理し余裕コンピュティングパワーを他のジョブに任すとかの仕事は今までサーバー何百台位での話ではなくなりました。
例えば1番サーバーにCPUを100%使って100TBのデータを読み込もうとしました。しかし、サーバー間のネットワークが10Gbpsです。100TBのデータをストレージから読み込むだけで約100,000秒(約28時間)かかります。そしてMLをします。書き込みます。1週間かかっても終わりません。
といことが多いです。(実際にあった話です。)
データの容量が大きくなるほどデータの管理技術によって維持費用は全然変わります。
例えば、私のお客さんのところに実際の話です。
現在のデータは75TB、増え続けてMLまで含めて5倍の375TBまでデータが必要です。
それで5年間データを収集するとして1.76PBを用意しました。
SIerさんからの見積もりは約8億円
私なら1億円以下で抑えられます。勿論この以下にも抑えられる方多いと思いますが、速度の維持及びメンテナンス・運用サービス含めての話です。
高速データ伝送及びPreloadingというCDN(Contents Delivery Network)技術そして地域毎に分散されたデータの整合性を維持しながらreplicaを作る方法それを負荷分散するGLB(Global Load Balancing)技術等。
これが分散技術の力だと思います。
このアーキテクチャを作れる人がData ScientistのHackerと呼ばれる部門ですね。
コメント
コメントを投稿